<나는 DB에 대한 개념 자체가 없기 때문에 DB 이해에 좀 더 중점을 두었다.>
가시다님이 요번에는 오퍼레이터에 대해서 알려주셨다.
참고) 주황색은 향후 지식이 더 보완되면 보충해야될 부분이다. 아직 제대로 이해가 안간 부분.
도대체 Operator가 뭐고 왜 쓰는걸까?
일단 이름만 보면, 운영을 해주는 놈이다.
쿠버네티스의 Operator pattern의 정의를 찾아보자.

자, 그럼 Operator가 뭔지는 알았다.
뭔가 소프트웨어를 자동으로 운영해주는 방법 자체를 말하는건가보군!
그럼 왜 쓰는걸까?

Operator의 지상 최대 목표는 human operator가 해야 하는 루틴한 일 (서비스 운영, 배포, 문제 생겼을 시 대응)을 대신하는 것이다.
Operator로 반복적인 작업들을 자동화할 수 있다.
이번에는 Operator에서 쓰이는 용어들을 알아보자.
CRD (Custom Resource Definition) : 오퍼레이터로 사용할 상태 관리용 객체들의 spec을 정의
CR (Custom Resource) : CRD의 spec을 지키는 객체들의 실제 상태 데이터 조합
CC (Custom Controller) : CR의 상태를 기준으로 현재의 상태를, 규정한 상태로 처리하기 위한 컨트롤 루프
기본적으로 쿠버네티스는 current state와 desired state를 일치시키는데 그 목적이 있다.
지금 보니, Operator도 딱 그런 것 같다.
-> Custom Controller는 Custom Resource가 Custom Resource Definition을 준수하는지 계속 loop를 돌면서 체크하고, 맞게 조정하는거다!
즉, Operator는 1) 구성, 2) 배포, 3) Custom Controller 연계 및 실행 등을 모두 합쳐 놓은 것을 말한다.
참고) Operator는 Helm 기능을 포함하며, 배포 업그레이드 운영까지 확장해서 관리한다.
음 그래도 확 와닿지가 않으니까 실제 예시를 한번 보자.

음... 이걸 이해하기 위해선 프로메테우스의 아키텍쳐를 볼 필요가 있겠다.
혹시 모르시는 분들을 위해서... 프로메테우스는 모니터링 툴이다!

Service Discovery : Prometheus는 기본적으로 모니터링 대상 목록을 유지하고 있으며, 대상에 대한 IP나 기타 접속 정보를 설정 파일에 주어서 모니터링 정보를 가져오는 방식을 사용한다.
잠깐) Service Discovery란?
MSA와 같은 분산 환경은 서비스간의 원격 호출로 구성이 된다. 원격 서비스 호출은 IP 주소와 포트를 이용한다.
클라우드 환경이 되면서 서비스가 오토 스케일링등에 의해 동적으로 생성되거나, 컨테이너 기반 배포로 서비스의 IP가 동적으로 변경되는 일이 잦아졌다. 그래서 서비스 클라이언트가 서비스를 호출할 때 서비스의 위치 (즉 IP와 포트)를 알아낼 수 있는 기능이 필요한데, 이게 바로 Service Discovery다.
MSA에서 Service discovery 패턴
MSA에서 Service discovery 패턴의 이해 조대협 (http://bcho.tistory.com) MSA와 같은 분산 환경은 서비스 간의 원격 호출로 구성이 된다. 원격 서비스 호출은 IP 주소와 포트를 이용하는 방식이 되는다. 클라
bcho.tistory.com
생각을 해보자. 우리는 지금 쿠버네티스 위에 Prometheus를 올렸다.
그러면
Service Discovery : Prometheus는 기본적으로 모니터링 대상 목록을 유지하고 있으며, 대상에 대한 IP나 기타 접속 정보를 설정 파일에 주어서 모니터링 정보를 가져오는 방식을 사용한다.
요거를 봤을 때, 모니터링 대상에 대한 정보가 바뀌면, 딱 봐도 pod에 수정된 conf를 넣고 재배포해야하는 번거로운 일이 생길 것 같다.
그럼 이걸 자동화해준다면? 개꿀인 것이다.
아하, 그래서 Prometheus Operator를 쓰는거군. 납득이 간다.
그러면 이번엔 좀 더 general하게 Operator의 작동 매커니즘을 보자.

CRD (yaml)을 kubectl로 쿠버네티스 클러스터에 배포하면, Custom Controller가 API 서버를 통해서 Custom Resource가 CRD와 일치하는지 끊임없이 확인하고 맞춘다.
이번엔 쿠버네티스의 작동 매커니즘을 보자.

음, 다 비슷하다. 유일한 차이는 쿠버네티스는 Controller가 Master Node 안에 있다는 것?
그 외에는 Concept이 완전히 동일함을 알 수 있다.
별 것 아니군. 넘어가자.
이번에는 MySQL 8.0에 대해 알아보자.
와... 데이터베이스에 대해서 꼭 배우고 싶었는데, 이 스터디로 인해서 드디어 배우게 되었다!

데이터베이스 운영에서 가장 중요한 두 가지는 Scalability확장성와 Availability가용성 이다.
가시다님 노션을 보면
데이터베이스 운영에서 가장 중요한 두가지 : 확장성과 가용성 -> Replication복제
이렇게 되어있는데 음 아직 복제는 이해가 안간다.
일단 넘어가자. -> 해결) Replication을 함으로써 확장성과 가용성을 보장한다는 뜻이었다. 별 것 아니네.
참고)
복제 관련한 용어가 변경되었다고 한다. (MySQL 8.0.23 버전부터)
Master -> Source -> Primary
Slave -> Replica -> Secondary
multithreaded slave -> multithreaded applier
'명령어, 시스템 변수, PS 테이블명, process list, replica status'등에 용어 변경 적용
예시) SHOW SLAVE STATUE -> SHOW REPLICA STATUS
용어는 대충 삘로 알겠는데, "Replica" 이거는 이것만 봤을 때 얘가 Slave라는게 직관적으로 와닿지 않을 것 같다.
다음에 분명히 까먹겠지만 어쨌든 일단은 알고 넘어가자!
이번엔 데이터베이스에 대한 간단한 개념을 짚고 넘어가자.
데이터베이스에서 엄청나게 나오는 단위가 있다.
바로 Transaction이다.
이게 뭘까?
Transaction은 기본적으로 반드시 한번에 수행되어야 하는 작업들의 묶음을 의미한다.
(= 부분적으로 실행되는게 최악이다. 차라리 아예 실행이 안되거나, 전부 실행이 되어야 한다. 요걸 All or Nothing이라구 한다.)
음... Transaction이 굳이 왜 필요할까?
도대체 작업들이 한번에 수행되는게 왜 필요하단말야?
생각을 해보자.
내가 계좌에서 만원을 내 친구한테 송금한다구 하자.
현재 내 계좌 잔고 : 20000원
내 친구 계좌 잔고 : 3000원
그러면 송금과 동시에
현재 내 계좌 잔고 : 20000원 - 10000원
내 친구 계좌 잔고 : 3000원 + 10000원
두 개의 Task가 같이 일어나야 한다.
다시 다시.
이게 0시 0분 0초 완전히 같은 시간에 일어나야 한다는게 아니고, (parallelism)
내 계좌에서 10000원이 빠졌으면 내 친구 계좌에 10000원이 늘어나야한다는거다. (concurrency)
-> 이걸 Transaction이 1)Atomicity원자성을 지녔다고 한다.
왜? 더 분해할 수가 없거든. Task를.. 마치 원자처럼...
만약에 부분적으로 성공했다면? 아까 말했다. 이게 최악이라고.
내 계좌에서 돈은 빠져 나갔는데 내 친구 계좌에서 돈이 안늘어나면 어떡해? 그냥 돈이 증발한거잖아.
이럴 경우 당연히 아예 모든 Tasks가 없었던 것처럼 되돌려야 한다.
이걸 Rollback이라고 한다.
글구 모든 Tasks가 정상적으로 수행이 되면 이를 실제 데이터베이스에 반영하고, 이를 Transaction Commit이라고 한다.
<-> 이 말은 곧, Commit이 되기 전까지는 데이터가 임시로 어딘가에 따로 저장이 되는 것을 알 수 있다.
다시 말해 Rollback or Commit 둘 중 하나가 수행되어야 Transaction이 종료되는거다.
2)Consistency일관성
어떠한 컬럼의 속성이 수정되었다면 Trigger를 통해 일관적으로 모든 데이터베이스에 적용해야 한다.
3)Durability지속성
트랜잭션이 성공적으로 수행되어 커밋되었다면 어떠한 문제가 발생하더라도 데이터베이스에 그 내용이 영원히 지속되어야한다.
이를 위해 모든 Transaction은 Log로 남겨져 어떠한 장애에도 대비할 수 있도록 한다.
4)Isolation독립성
어떤 Transaction 수행 시에 다른 Transaction이 작업에 끼어들 수 없고 갓 Transaction을 독립적으로 수행해야 한다.
Transaction은 격리 수준 설정을 통한 독립성 보장으로 동일한 데이터를 동시에 read/write 했을 때 벌어질 수 있는 문제를 미연에 방지한다.
근데 또 완전히 한 Transaction이 끝나고 다른 Transaction을 수행해야 된다고 하면 너무 비효율적이다.
이렇게 데이터베이스에 저장된 데이터의 무결성과 동시성의 성능을 지키기 위해 Transaction의 설정이 중요하다.
MySQL Replication
[NHN Cloud]
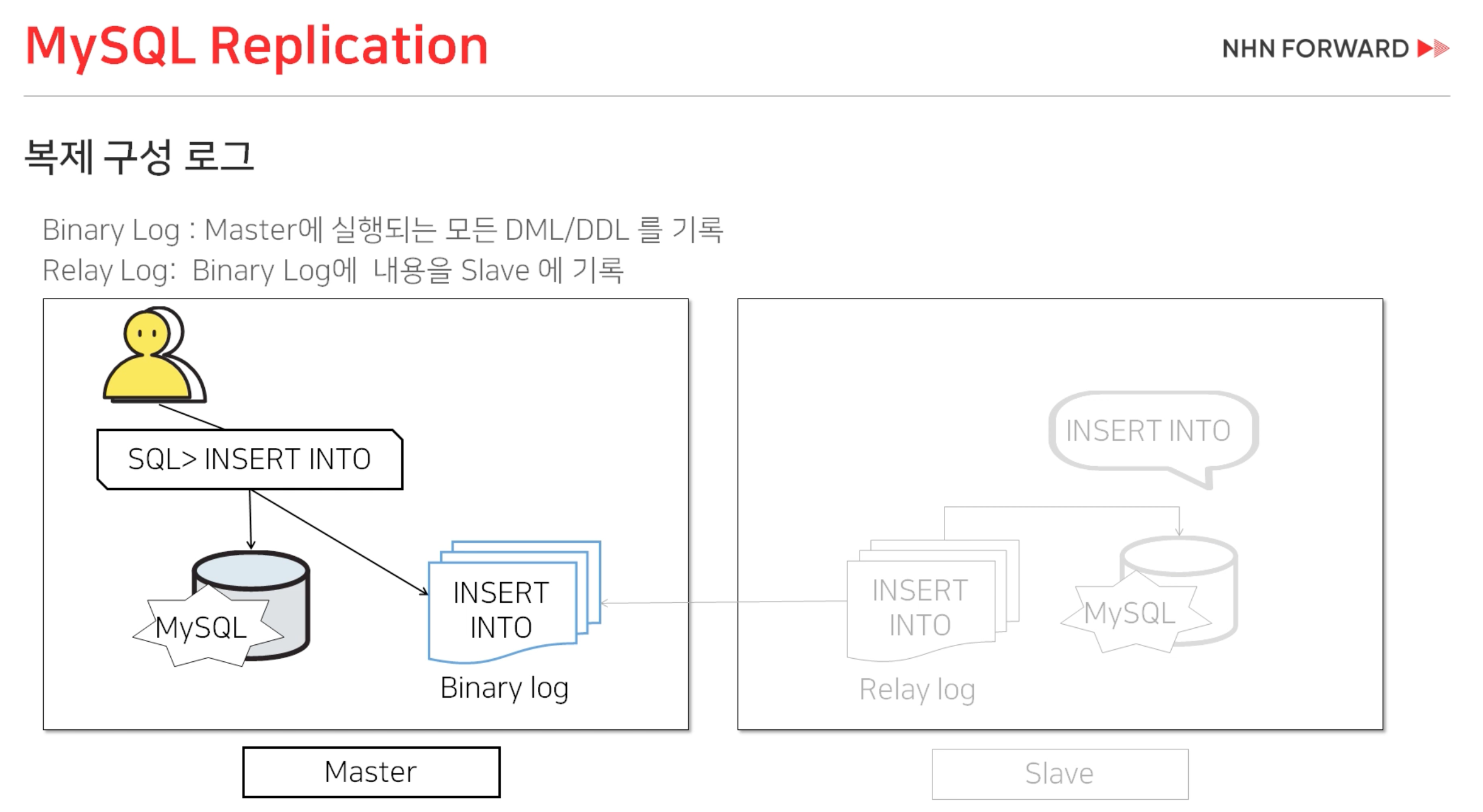
왼쪽 노란색 : 클라이언트
클라이언트에서 쿼리를 실행하면, 데이터가 변경되는 INSERT, UPDATE, DELETE의 경우에는 Binary log라는 파일 로그에 기록이 되고 MySQL DB에 실행이 된다.
그리고 Slave에서는 Binary log를 감시하다가 새로운 Query가 들어오면 Slave의 Relay log로 가져오게 되고, Slave의 DB에 Query를 실행함으로써 Master의 데이터가 Slave에 적용되게 된다.
-> 사실상 지금까지 실행한 Query의 히스토리 백업 같은 역할이구만.
MySQL Replication 일관성 보장

1. 클라이언트가 쿼리 실행
2. Binary log에 기록, MySQL DB에 실행
3. Slave에서는 Binary log를 감시하다 새로운 쿼리가 작성되면 그 쿼리를 요청
4. Slave의 요청을 받은 Master는 Binary log를 Slave에 전달하고, 전달됐음을 보장받기 위해 응답을 기다린다.
5. Slave는 Master로부터 데이터를 받은 뒤, Master에게 잘 받았다는 ACK를 보내고
6. Master는 Slave에게 응답을 리턴받은 후 클라이언트에게 OK 메시지를 보내게 된다.
만약 Slave가 여러 대라면?
Multi-Slave 환경

1. 클라이언트가 쿼리를 실행
2. Master의 Binary log에 저장되고 DB에 실행
3. 각 Slave에서는 Binary log를 감시하다가 새로운 쿼리가 작성되면 그 쿼리를 요청
4. Master는 각 Slave에 Binary log를 보내주고, ACK 응답 기다림.
5. Slave는 Master에게 잘 받았다는 ACK 응답을 보내줌.
*6. Master는 하나의 Slave한테라도 응답을 받게 되면, 클라이언트에게 200 응답을 보냄.
-> 하나의 Relay log 파일에 작성되면 완료.
그럼 내 의문) 그럼 전달 못받은 Slave는 데이터가 달라질텐데 어떡해?
MMM : Multi-Master Replication Manager

의문) Slave를 추가하는 것과 Master를 추가하는 것의 차이는 어떤게 있을까?
-> 해결) 아, 영상을 더 보니까 Active-Active 구조가 아니라 Active-Standby 구조인듯 하다.
그럼 뭐 이해가지. Fail-over만을 위한거니깐.
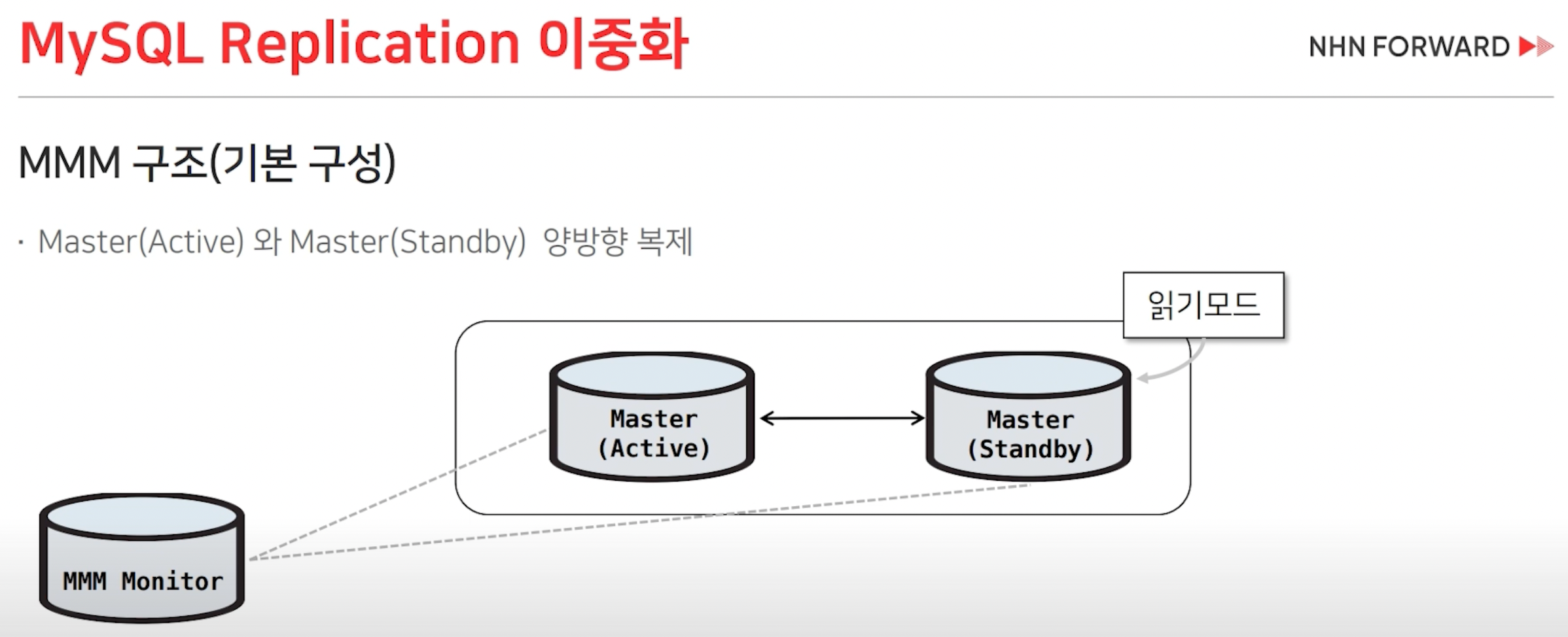
MMM Failover를 할 때, 복제가 깨지는 경우가 있대.
어떨 때 깨지는지 보자.

자, Master(Active), Master(Standby), Slave가 있다고 하자.
이때, Master(Standby)도 Slave처럼 취급하는 것 같다. 왜냐하면, 지금 당장 Master는 아니니깐. Master의 예비지.
Master(Active)에서 각 디비에 (101, 'B')를 보내게 되고, Slave만 이를 받았다고 하자.
그럼 Master(Active)는 하나의 Relay log에만 저장이 되어도 클라이언트에게 200 응답을 보내므로 Replication이 정상 수행이 된
상태인데 사실 Master(Standby)는 (101,'B')가 없는 상태다.
이 상태에서 Master(Active)가 down되면, failover로 인해 Master(Standby)가 Master로 승격되게 된다.
이때, 문제가 발생한다!
Master(Standby)에는 (101,'B')가 없으므로, 다시 그 값이 들어오게 되고 (이 부분 애매. 이미 끝났는데 왜 들어오지? 음.)
Binary log가 다시 Relay log로 전파되게 되는데, Slave는 이미 (101,'B')를 갖고 있으므로
중복 key 오류로 복제가 깨지게 된다.
-> Multi Slave 환경에서는 복제 Crash 가능성이 미약하지만 존재한다.
이걸 극복하기 위해 MHA라는게 나왔다는데 이건 패스.
MySQL의 복제 동기화 방식
1. 비동기 복제
2. 반동기 복제

비동기 복제는 Master가 Slave에 제대로 적용이 됐는지 확인을 안한다. 그래서 Master에 장애가 발생하면 Master에서 최근까지 적용된 트랜잭션이 Slave로 전송되지 않을 수 있다.
ㄴ 이거 뭔 소린지 이해가 안가는데?

ㄴ 이게 위 NHN에서 설명한거네. Slave에서 ACK 받고 클라이언트에게 OK 보내는거.
주의)
1. 전송이 보장된 것이지 적용이 보장된 것은 아니다. (Commit이 보장되지 않는다는 소리인 것 같아)
2. Slave에서 응답을 기다리기 때문에, 비동기 방식보다 트랜잭션 처리가 느려질 수 있다.
3. 반동기 복제에서는 Slave에서 응답이 안오면 무제한으로 기다릴 수 있기 때문에, timeout을 걸구 그 시간이 넘으면 비동기 복제로 전환한다.
MySQL Group Replication 구축
https://saramin.github.io/2021-09-28-mysql-group-replication/
MySQL Group Replication 구축
MySQL Group Replication 구축 사례
saramin.github.io
group replication이 머지?
요거는 일단 넘어갔다가 다시 돌아오자. 내용은 읽어볼만함.
음... 이번엔 MySQL의 HA solution에 대해 알아보자.
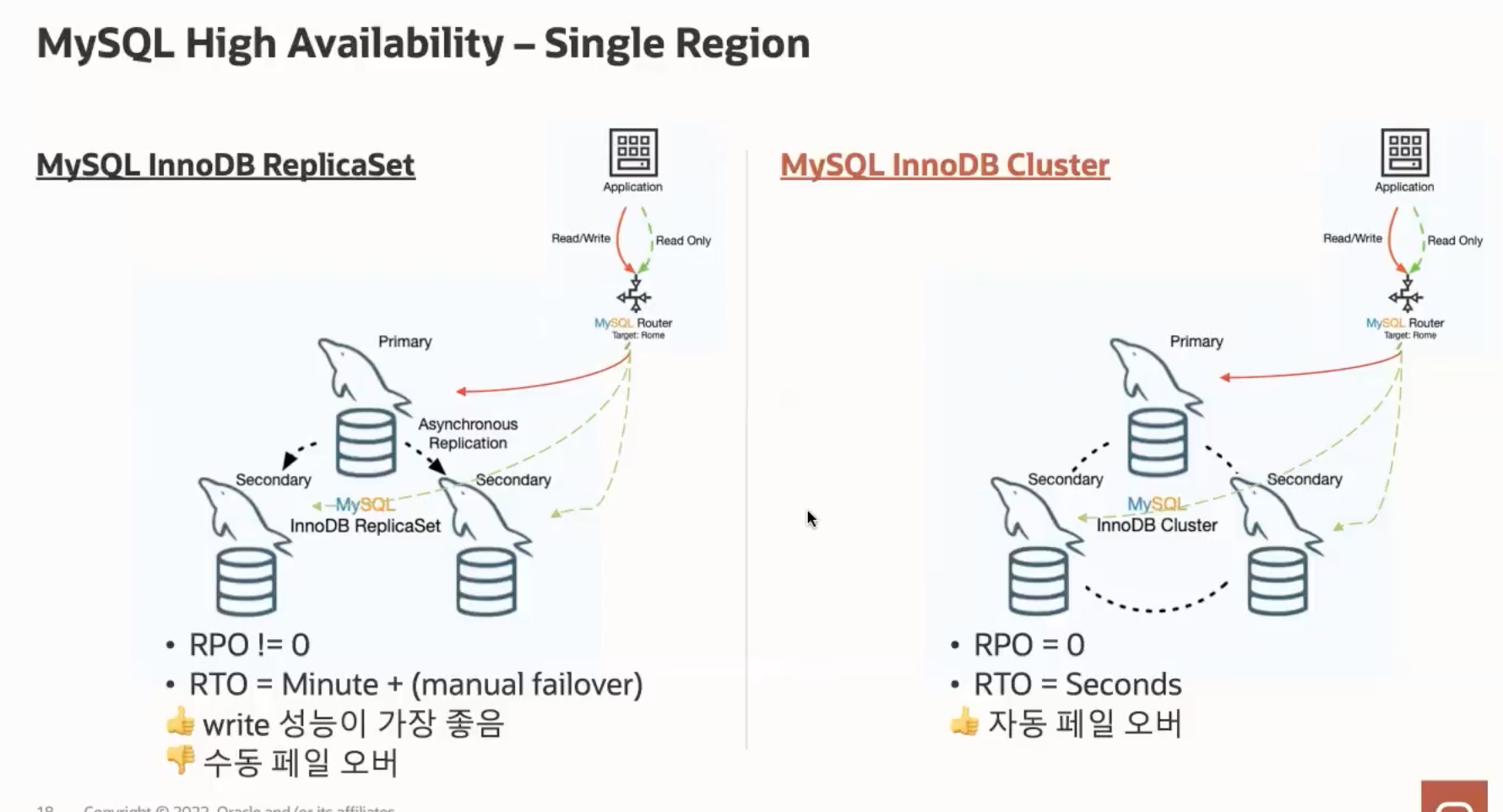
사실 InnoDB라는걸 난생 처음 들어봐서 이게 뭔지 잘 모르겠다.
먼가 합의를 한다는데... 일단 넘어가자.
MySQL 아키텍쳐

MySQL의 아키텍처는 다음과 같이 크게 4가지로 분류할 수 있다구 한다. (나는 잘 모르는데 아는 것처럼 단정 지을 수 없으므로..)
1. MySQL 접속 클라이언트
2. MySQL 엔진
3. MySQL 스토리지 엔진
4. 운영체제, 하드웨어

잘 이해 안가니까 일단 넘어가자.

본 그림은 데이터베이스의 상태를 나타낸다.
InnoDB 버퍼풀 : 변경된 데이터를 디스크에 반영하기 전까지 잠시 버퍼링하는 공간
Undo log : 변경되기 이전 데이터를 백업해두는 공간
-> 그러면.. 변경되기 이전 데이터랑 변경된 데이터 모두 메모리에 올라가있네!
그래서 데이터베이스는 항상 메모리 점유율이 높은 것 같다..? 물론 캐싱도 있겠지만..

INSERT INTO USER (id, name, hobby) VALUES (1, 유재석, 독서) 를 입력하면
InnoDB 버퍼풀의 USER 테이블 레코드에 (1, 유재석, 독서)가 기록된다.
그런데 UPDATE로 (1,유재석,코딩)으로 바꿔버리면, 언두 로그에 기존 데이터인 (1,독서)를 저장하게 된다.
(아직 커밋 안한 상태라고 가정)
그런데 만약 이 상황에서 다른 트랜잭션이 유재석 레코드를 조회하면 무슨 일이 벌어질까?
-> 트랜잭션 격리 레벨에 따라 다르게 나온다.
READ_UNCOMMITTED로 조회하면 InnoDB 버퍼풀에 있는 데이터가 나오고
READ_COMMITTED or REPETABLE_READ or SERIALIZABLE로 조회하면 Undo log에 있는 데이터가 나온다.
이렇게 트랜젝션 격리 레벨에 따라 조회되는 데이터가 달라지게 하는 기술을 MVCC라고 한다!
Multi Version Concurrency Control : 다양한 버전이 동시에 관리된다.
'Computer Science > Database' 카테고리의 다른 글
| MSA 환경에서 데이터 관리를 위한 필수 사항: 고가용성과 데이터 동기화 (퍼옴) (0) | 2022.07.20 |
|---|---|
| DOIK - MongoDB (NoSQL 학습) (0) | 2022.06.26 |
| KAFKA (카프카) 공부해보자 (0) | 2022.06.12 |
| 트랜잭션과 ACID 특성을 보장하는 방법 (+TPS, DB의 메모리 점유율이 항상 높은 이유) (0) | 2022.06.03 |
| DB RDBMS의 한계와 NoSQL을 사용하는 이유 (0) | 2022.03.30 |