Controller
- 1개 이상의 파드를 제어할 수 있는 오브젝트
- ReplicationController (아 맞다, RC랑 RS랑 다른거였지..!! -> 뭐가 달랐지?
1) RS는 레이블 검색할 때 in, notin, exists같은 연산자 지원함.
2) Deployment와 같이 쓰이면 RollingUpdate 지원함.
- ReplicaSet
- Deployment
------------------ 여기까지는 Control Plane의 Kubernetes Scheduler 판단 하에 적절한 node에 띄워줌.
- DaemonSet
- Job
- CronJob
- StatefulSet
DaemonSet
- 일반적으로 Control Plane을 제외한 워커 노드에 1개씩 파드가 띄워질 수 있도록 하는 Controller
- 파드를 실행하는 노드가 Control Plane 이거나 nodeSelector로 파드를 실행할 노드가 정해지지 않은 경우 모든 노드에서 파드가 실행됨
일반적으로 Control Plane에는 아무런 pod을 안놓는게 맞다.
Minikube라는게 있는데, 이건 테스트 목적으로 Control Plane이 worker node의 역할까지 겸하는 것이다.
-> 그럼 얼케 Control Plane에는 Pod 배치가 안되는거야?
ROLES이 master로 되어 있기 때문임.

-> taint, tolerance 라는거에서 나온대
kubectl get all하면 pod과 관련된 모든 정보들이 다 뜨는거래.




이번엔 node selector로 node의 label에 따라서 먼가 스케쥴링 해보려고 하나봐?




Job
- 파드의 애플리케이션이 실행 완료/종료 되는 것에 초점을 맞춘 Controller
- 한번만 실행될 작업을 정의하는 Controller
spec.completions: 작업을 성공으로 판단하기 위한 정상종료 파드 갯수
spec.parallelism : 병렬성 지정하는 값으로 동시에 실행될 파드 갯수
restartPolicy : 재시작 정책
Always : 종료/실패시 항상 재시작
OnFailure : 실채시 재시작 (정상 종료시 재시작하지 않음)
Never : 종료 또는 오류시 절대 재시작하지 않음
CronJob
- 주기적으로 실행될 작업을 예약할 때 사용하는 Controller
spec.schedule : min hour day month weekday
spec.startingDeadlineSeconds : 정의된 시간 내에 재시작 되지 않으면 종료됨
spec.concurrencyPolicy :
Allow : 작업을 동시에 실행 허용
Forbid : 작업을 동시에 실행하는 것을 금지
Replace : 기존 작업을 대체하며 새로운 파드가 실행됨
StatefulSet
- 여러개의 동일한 파드를 실행하는 Controller로 각 파드의 애플리케이션이 고유한 상태를 가지도록 하는 Controller

쿠버네티스 초창기에는 StatefulSet을 PetSet이라구 불렀어. (나중에 동물 경시 사상이라고 이름 바꿨대)
원래 기본적으로 deployment에 replicaset들이 물리게 되면, 이름이 deploy-a-xxxxxx-xxxxxxx 이런식으로 할당을 받게 돼. 왜? 모든 pod이 저장소를 공유하거든. 그러니까 pod끼리 구분될 필요가 없는거야.
그런데 StatefulSet은 deploy-a-0, deploy-a-1, deploy-a-2 이렇게 잡혀.
왜냐하면, 각각의 pod이 고유의 저장소를 갖고 있으니까 서로 구분될 필요가 있거든.
그래서 방목해서 키우는 가축과 집에서 키우는 애완동물의 차이로 비유 할 수 있겠다 이거지.

kubectl create -f statefulset.yaml
kubectl create -f statefulset-service.yaml



StatefulSet을 삭제하면, (kubectl delete statefulsets web)
web-2, web-1, web-0 이런 순서로 삭제되게 된다. (만들어질 때도 web-0, web-1, web-2 순서대로 생긴다.)
watch kubectl get pods 하면 볼 수 있다.
"근데 아직 각 Pod에 Volume을 안달았당"
그럼 이런 순서 없이 pod를 종료할 수는 없을까? (왜? 그래야 하는 이유가 있나?? 아~ 순서가 있을 수도 있으니까??)
먼 소리야 순서가 없이 종료하는거 말한건데 ㅡㅡ
parallel을 쓰면 pod을 순서 없이 종료할 수 있다.
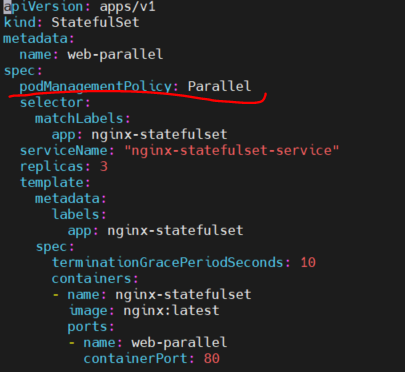
이번에는 statefulset으로 pod을 업데이트 해보자.
kubectl edit이랑 kubectl apply -f dd.yaml 이 두 개로 업뎃 가능함.

자, kubectl edit으로 running container pod의 값을 변경하는 것과
kubectl apply -f로 running container pod의 값을 변경하는 것의 차이가 무엇일까?
-> kubectl edit은 지금 실행하고 있는 container pod에만 적용이 된다.
(표현을 container가 아니라 pod으로 써야 맞는 것 아닌가 싶음. 왜냐하면 kubectl이 조작할 수 있는 최소 단위는 pod이잖아. pod을 조작하는거지 container를 직접 조작하는 일은 없었으니까 지금까지..)
yaml 파일은 건드린 적이 없으므로, 다음 pod을 생성할 때는 다시 변경/추가하지 않은 상태의 pod이 만들어진다.
-> kubectl apply -f를 한다는 뜻은, yaml 파일 내에서 수정을 했다는 뜻이므로, 앞으로 만들어지는 모든 pod에 적용이 된다.

만약에 지금 운영중인 pod는 건드리지 않고, 새롭게 만들어지는 pod에만 적용이 되게 하려면 얼케야댈까?
-> updateStrategy를 onDelete로.
이걸 하면 지금 운영중인 pod에는 편집을 해도 적용이 안되고, 운영중인 pod를 수동으로 지웠을 때,
새로운 값이 추가/변경된 pod이 생성된다.


이제 kubectl edit statefulset web-ondelete를 통해서 값을 바꿔보자


값이 안바뀌었다.
그럼 이번에는 web-ondelete-0을 지우고 새롭게 만들어지는 pod은 값이 바뀌나 보자.

잘 보면, statefulset은 web-ondelete-0이 지워지면, web-ondelete-4를 만드는게 아니라
다시 똑같은 web-ondelete-0을 만든다.

--------
서비스 오브젝트가 뭐야?
이게 왜 필요해?
뭔지는 아래에 써있으니까 왜 필요한지부터 알아보자.
쿠버네티스의 pod은 기본적으로 생성될 때 ip를 dhcp 서버에게서 할당받게 된다.
그런데 컨테이너는 알다시피 쉽게 사라지고 생성되잖아.
쿠버네티스는 msa를 위해서 만들어진건데, 그럼 클라이언트들이 각 서비스에 접근하기가 어려워져.
이 서비스 오브젝트에 부여된 ip 주소는 서비스 오브젝트가 종료되기 전까지 변하지 않는다.
그래서 서비스 오브젝트가 고정된 ip를 제공해줄 수 있다.
pod에 접근하기 쉽게 ip를 제공해주는 것이 서비스 오브젝트.
서비스 (우리가 일반적으로 생각하는 서비스가 아니야. 서비스 오브젝트. 도대체 왜 이름을 서비스로 했을까..)
여러 파드에 단일 진입점을 제공하는 오브젝트
서비스 오브젝트에 부여된 IP 주소는 해당 서비스가 종료될 때까지 변하지 않음.
서비스 타입
- ClusterIP : 클러스터 내에서 접근 가능한 IP 주소를 제공하며 클러스터 외부에서는 접근 불가함.

- NodePort : 클러스터의 모든 노드에 동일한 포트를 개방하는 서비스 타입
클러스터 외부에서 해당 포트로 접근하면 연결된 파드로 트래픽이 전달됨
NodePort 타입 생성시 ClusterIP도 자동으로 생성됨 (30000-32767 범위의 포트 번호 사용)

근데 좀 이해가 안가.
둘 중 하나만 해야 하는 것 아닌가?
모든 노드 통틀어서 ip가 하나밖에 없게 해서 NAT같은 개념으로 쓰든가
아니면 모든 노드에 ip가 각각 있는 대신, 각각 노드에만 접근이 되든가
후자는 이게 오케스트레이션 툴이니까 개념적으로 그러면 안된다고 해도,
전자는 괜찮지 않나? 모든 노드에 개별적으로 ip/도메인이 있고,
그 각각의 ip로 접근한게 왜 결국 모든 노드로 접근하는 결과랑 같은거야??
무엇을 위해서 이렇게 만든거지?
대충 추론해보자면, VIP를 앞단에 두려면 뭔가 서비스 오브젝트(?)를 하나 더 만들어야 하니까
그냥 이렇게 처리한게 아닐까...? 그래도 굳이..? 라는 생각이 드네?
ㄴ 2022/4/1 생각해봤는데, Node는 서버잖아. 그럼 당연히 네트워크가 연결된 서버에는 IP가 있을거아냐?
일단 그건 어쩔 수 없는거고, 그럼에도 불구하고 모든 노드가 하나의 pool로서 작동하게 하기 위해서 한 노드로 접속해도 다른 노드로 redirection할 수 있게 한 것 같아.
질문)

답변)
만약 80번 포트를 쓰고 NodePort로 지정한 애플리케이션 A, 81번 포트를 쓰고 NodePort로 지정한 애플리케이션 B가 있으면 모든 노드에서 80, 81번 포트가 열린다.
그런데~ 말했다시피, NodePort는 30000~32767번 포트를 사용하므로 80, 81번은 안열린다. ㅋ
그래서 NodePort는 쿠버네티스 차원에서의 일종의 로드밸런서 역할도 겸하고 있다고 할 수 있다.
- LoadBalancer : 일반적으로 클라우드 서비스를 이용하는 경우에 사용 가능한 네트워크 서비스 타입

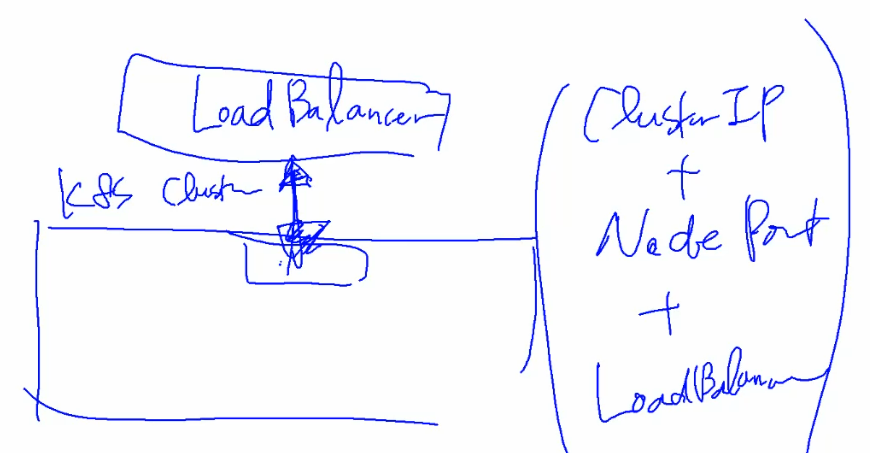
여기서 Loadbalancer는 Kubernetes Cluster 외부에 있는 물리적인 장비를 통해서 구현된다.
서비스 오브젝트를 한번 만들어서 사용해보자
kubectl create -f clusterip.yaml

근데 이걸 만들기 전에, 이 서비스 오브젝트를 사용하는 뭔가가 존재해야돼. pod든 뭐든. (<- 그럼 pod 말고 또 머가 됨?)
그래서 deployment를 한번 만들어보자구.
kubectl create deployment nginx-deploy --image=nginx:latest --replicas=3
(이러면 안되지. deploy 이름을 nginx-for-svc로 해야 위에 쓴 ClusterIP service가 얘를 찾아내서 관리할거아냐?

쿠버 클러스터 안에서 ClusterIP로 접근 테스트 한번 해보자
kubectl run -it network-multitool --image devops2341/network-multitool:latest
일케 하면 shell이 열림.


Kubernetes 네트워크 서비스 목록 확인
kubectl get services
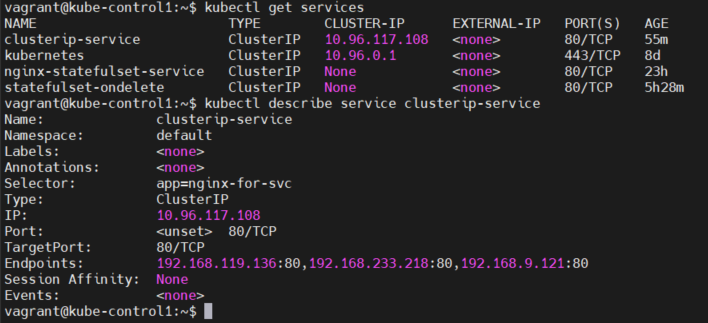

아까 위에서 clusterip 서비스를 만들 때, kubectl create -f clusterip.yaml로 만들었짜나.
근데

이렇게 selector로 app name이 nginx-for-svc인 애만 연결되게 해놨었거든?
근데 아까 잘 들어가졌잖아. 왜???
왜냐하면 아~까 실습에서 미리 nginx-for-svc를 만들어놨었거든.... 지금 한거랑 별개로...
그래서 들어가진거임. ㅋㅋㅋ
내 의문은, 도대체 얼케 지금 만든 nginx-deploy랑 ClusterIP Service랑 연결을 시키는거야? 라고 생각했는데,
deployment의 name으로 연결하는거였어. ㅎ
이번에는 NodePort Service 사용해보자.






아 지금 뭔가 이상해 오개념이 있는거같아
control-plane이랑 bash 둘 다 지금 http://10.111.219.182랑 http://192.168.119.140 둘 다 접속이 되거든?
근데! 192.168.119.140:30080 하면 접속이 안돼. 뭐야!!!!!
192.168.119.140 이거 외부를 위한 IP 아니었어?
어라 뭐지. 나는 NodePort의 Endpoints가 노드의 IP인줄 알았는데 다른데???
Node의 IP는 192.168.56.21인데??
curl http://192.168.56.21:30080

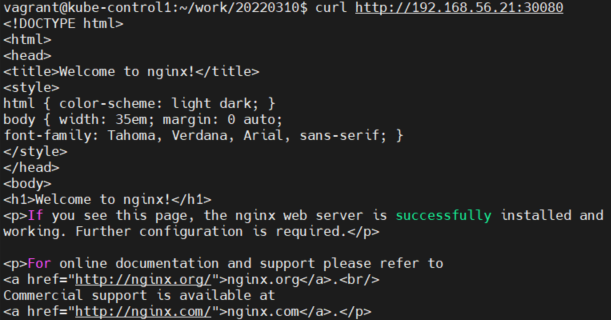
노드의 IP로 접속하니까 되네!!!!!!!

당근 80번 포트로 접속하는건 막혀있고.
그러면 도대체...
여기서 Endpoints는 뭐야.....???


완전 Kubernetes Cluster 바깥의 cmd에서 접근하면,

참고)
VirtualBox 쓰는 사람은 node의 ip가 순차적으로 192.168.56.21~
VMware 쓰는 사람은 node의 ip가 순차적으로 192.168.100.21~ 이래.

https://honggg0801.tistory.com/48
Kubernetes - Service
Service란 쿠버네티스 외부 또는 내부에서 Pod에 접근할 때 사용하는 기능이다. service를 사용하는 이유는 Pod는 서버와 같이 영구적인 것이 아니라 일회적인 것이기 때문이다. 서버는 문제가 생기면
honggg0801.tistory.com
로드 밸런서 실습 해보자


EXTERNAL-IP는 계~속 pending일거임. 외부 장비가 없으니깐.
curl http://192.168.56.21:31294

뭐지 External IP 없는데도 Node IP로 접근이 되네??
아 당연히 되겠구나 생각해보니까!
Loadbalancer IP가 있다고 Node IP로 접근이 막히는건 아니지.
근데 Node IP : Loadbalancer Port로 접근이 되는게 좀 신기하네.
[실습] On-Premise 환경에서 LoadBalancer 사용해보기


On-Prem에서도 LB를 쓸 수 있게, Pod 형태로 지원해준다!
개꿀팁 참고)
MetalLB 홈페이지에서 그냥 최신 버전을 다운받으려고 하면 설치가 제대로 안될 수 있다.
왜? 최신 MetalLB는 최신 Kubernetes를 기준으로 개발한거라 이전 버전과 지원 리소스가 달라서 호환이 안될 수가 있거든.
-> 그래서 강사님이 아래 링크를 주신거야. ㅋㅋ.
설치하기 전에 질문 하나)

ClusterIP < NodePort (ClusterIP 기능 포함) < LoadBalancer (ClusterIP + NodePort 기능 포함)
이렇게 되는거다.
즉, NodePort를 쓴다고 ClusterIP의 오브젝트가 따로 생기는 것이 아니고, NodePort가 ClusterIP의 역할까지 겸하고 있는 것이다. (매우 중요!!)
LoadBalancer도 이하 동문.
metallb namespace 구성
kubectl create -f https://raw.githubusercontent.com/metallb/metallb/v0.10.2/manifests/namespace.yaml
metallb 설치
kubectl create -f https://raw.githubusercontent.com/metallb/metallb/v0.10.2/manifests/metallb.yaml

에러난줄 알았는데 좀 기다리니까 Running 뜸 ㅋㅋ


vim metallb-config.yaml
=====
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: | (<- 이거 오타인줄 알았는데 오타가 아니었어 ㅡㅡ)
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.56.200-192.168.56.210 (metallb가 사용할 ip 대역)
======
metallb LoadBalancer 설정 적용
kubectl create -f metallb-config.yaml

계속 validating error가 뜨길래 뭐야 ㅅㅂ 했는데
config: 옆에 | 하나 붙여주니까 됨!
뭐지.. 무슨 뜻이지 저게?

-> Ansible 공부할 때 yaml 파일 공부하면서 나왔을거래.
한 줄로 입력받으려고 그런거라는데 솔직히 와닿지 않음.
왜 굳이 얘만 한 줄로 받아야됨?
아
보통 data는 하나의 줄에서 들어가야 한대. 여러 줄에 있는 데이터를 한 번에 넣어주기 위해서 |를 입력해서 읽어들이게 한거래. (key value로 되어있는걸 한번에 집어 넣으려고...? 근데 원래 data field가 아예 없었나 이 전에는?)
-> 헐 없었다. data 대신에 spec 들어가고 그 밑에 container가 들어갔었어!!!
https://lejewk.github.io/yaml-syntax/
yaml (yml) 문법 정리
기본 문법# 은 주석입니다. --- 문서의 시작을 나타내며 선택 사항 입니다.... 문서의 끝을 나타내며 선택 사항 입니다. 기본 표현key: value 로 표현하며, : 다음에는 무조건 공백 문자가 와야합니다.
lejewk.github.io
\n 을 포함하라는 뜻이라는데 아직도 뭔 소린지 모르겠다 ㅡㅡ..




Loadbalancer에서 80번에 대응되는 31562번 포트를 randomly 생성한 것 같다!
왜냐면 NodePort 역할도 같이 한다구 했으니깐!
질의 응답 받아주심)

'System Engineering > Kubernetes' 카테고리의 다른 글
| [쫌 어려움] 쿠버네티스 네트워크를 이해해보자 (0) | 2022.04.06 |
|---|---|
| kubernetes 8/17 (0) | 2022.04.03 |
| 쿠버네티스 잘 정리된 블로그 (subicura) (0) | 2022.03.31 |
| kubernetes 6/17 (0) | 2022.03.29 |
| github에 branch 만들고 push하기 (0) | 2022.03.29 |