기조 연설 :
Aurora
Redshift
Datalake : 데이터의 도서관. S3(store - Lake Formation(process) - Athena(search)
---
AWS 솔루션즈 아키텍트
아키텍쳐 현대화/ Modernization
변화에 빠르게 대응하고 민첩성을 개선하려고 함
* 수백만명의 사용자로 확장
* 글로벌 가용성
* 페타바이트의 데이터 처리
* 밀리초 단위로 응답
현대식 애플리케이션이란?
애자일 : 출시 시간 단축
모듈식 구성 : 기능을 빠르게 업데이트 가능 (혁신 향상)
향상된 안정성 : 테스트 절차 자동화, 개발 수명 주기 모든 단계 모니터링.
비용 절감 : 과도한 프로비저닝 비용 절감, 관리 비용 절감
현대화된 아키텍쳐란?
* 느슨하게 결합된 서비스로 설계
* 경량화된 컨테이너 혹은 서버리스 함수로 패키징
* 상태 비저장(stateless) 서비스와 상태 저장(stateful) 서비스를 분리하여 설계
* 탄력적이며 회복력있는 셀프-서비스 인프라스트럭처에 배포
* 서버 및 운영체제 종속성에서 격리
현대화를 위한 세 가지 경로
1. 관리형 컨테이너 서비스로 플랫폼 변경
2. 서버리스 아키텍쳐에서 새롭고 안전한 앱 빌드
3. 최신 dev+ops / 클라우드 네이티브 모델로 전환
Build Fast - Innovate more - Manage less
---
당근 마켓 채팅 시스템 현대화
AWS Serverless hero, 당근마켓 SW 엔지니어 변규현
월 평균 1600만명 사용자
처음에는 모놀리식으로 돌아가고 있었다.
(ECS)
변화하는 서비스의 형태
AS-IS
앱 사용자를 위한 서비스
유저와 직결되는 기능에 초점
한 서버에서 모든 기능을 구현 (코드 복잡도 증가 - 유지 보수 시간 증가)
신규 기능은 모놀리틱 서비스에서 함수 형태로 구현
규모가 커지며 길어지는 배포 주기
TO-BE
앱 사용자를 위한 서비스
사내 개발자를 위한 서비스 (해당 마이크로 서비스를 사용하는 개발자를 배려해서 API 디자인 / 사내 표준화)
개발자를 위한 다양한 기능을 제공해야함
API를 호출하는 형태로 지원
경량화된 서비스 구성 (서비스가 커지면 이슈가 생겼을 때 이슈를 트래킹하는 것도 쉽지 않고, 테스트가 점차 쌓여가며 배포에 걸리는 시간 또한 무시하지 못하게 된다.)
-> 마이크로 서비스의 도입
초기에 전체 채팅 데이터의 50%가 indexing에 쓰였대
PostgreSQL 쓸 때 채팅을 위한 테이블에 Vacuum이 일어나면 전체 DB에 많은 영향을 끼쳤고
종종 이로 인해 응답 시간이 저하됐대
가장 많은 사용량을 가진 채팅 데이터를 Main DB에 둘 수 없다고 판단해서
이를 분리하기 위해 채팅 API까지 전부 분리하는 마이크로서비스 프로젝트를 시작했다.
우선 채팅 데이터를 분리했다.
- Database Research 진행
* Managed Service일 것
* 최대한 운영에 대한 시간을 아껴야 함
* 데이터 용량 확장에 용이할 것 (테라, 페타 바이트 규모의 확장)
운영을 위한 개발자는 2명에 불과했다.
DynamoDB가 유일한 해답
응답도 수ms로 빠르다.
DynamoDB를 사용하면서 어려운 점
* 일반적인 SQL을 사용하지 못함 (현재는 PartiQL이라고 있대)
* 데이터를 가져오기 위해선 Query와 Scan으로 가져와야 함 (사실상 Query만 가지고 해야됨)
* Query는 인덱스를 건 Item만 가져올 수 있음
* Scan으로 filter를 걸 수 있음
* 다만 실제로 데이터를 전부 읽으면서 필터링해서 가져오기 때문에 비용 문제가 생길 수 있음
실 서비스에서는 사용하면 안됨.
인덱스를 잘 두어야하기 때문에 설계에 대해서 고민이 많이 필요함.
Full Scan으로 전체 데이터를 필터링하고 싶은 경우 DynamoDB기능으로는 거의 불가능함
(약 100만개 이상 item 존재하면 불가)
dynamoDB 사용하면, 별도의 분석을 위한 데이터 파이프라인을 구축해야됨.
gRPC, WebSocket, REST API
다음 스텝 : WebSocket으로 실시간 메시징
유저의 Session은 Redis, 데이터는 DB에서 관리하고 있다. (그래서 서버는 stateless 가능)
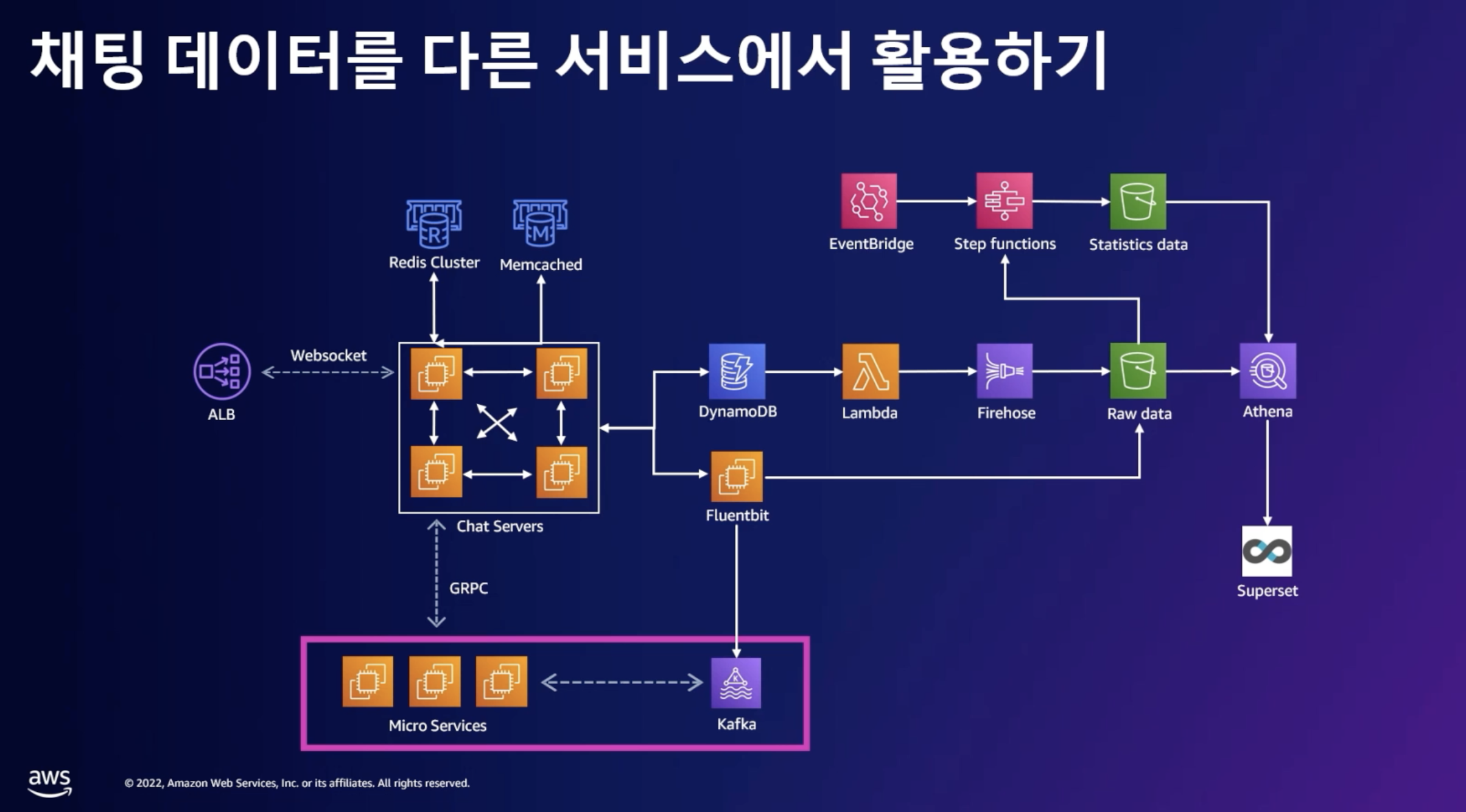
데이터 분석 PIPELINE
- DynamoDB Stream (DynamoDB에 있는 데이터를 실시간으로 처리)
- Lambda (Stream에 있는 데이터를 원하는 곳에 적재)
- Firehose (이벤트 버퍼를 받아 S3에 업로드)
- S3 (데이터 웨어하우스의 스토리지 역할)
- Athena (이러한 데이터 볼 수 있게 지원)
AWS Lambda가 하는 것
Json은 보통 nested structure이고, 불필요한 값 제거해서 key-value 구조로 재구성. (이게 조회 성능이 더 뛰어남)

'Cloud Webinar > AWS Summit' 카테고리의 다른 글
| AWS 2022 summit - 4 (대용량 트래픽 처리에 최적화, AWS 서버리스) (0) | 2022.05.11 |
|---|---|
| AWS 2022 summit - 3 (AWS CDK를 사용하여 모범사례 기반 Amazon EKS 클러스터 구축하기) (0) | 2022.05.11 |
| AWS 2022 summit -2 (DevOpsGuru 활용하기 / Observability 관찰 가능성이란?) (0) | 2022.05.10 |







최근댓글